Laboratorio: Análisis de Texto con Python - Detección de Bigramas y Colocaciones.
Objetivo
El objetivo de este laboratorio es aprender a utilizar herramientas de procesamiento de lenguaje natural (NLP) en Python, como NLTK y Gensim, para analizar un corpus de texto, extraer bigramas significativos y detectar colocaciones. Al finalizar el laboratorio, podrás aplicar estos conocimientos en tareas de análisis de texto y minería de datos en diversos campos de aplicación.
Requisitos Previos
- Conocimiento básico de Python, incluyendo la sintaxis y las estructuras de datos.
- Familiaridad con el procesamiento de texto y conceptos de procesamiento de lenguaje natural (NLP), como tokenización, lematización y extracción de características.
- Experiencia en el uso de bibliotecas populares de Python para NLP, como NLTK, spaCy y Gensim.
- Conocimiento de técnicas de modelado de lenguaje, como n-gramas, modelos de bolsa de palabras y modelos de lenguaje basados en redes neuronales.
- Comprensión de conceptos estadísticos básicos, como la frecuencia de palabras y la medida de información mutua puntual (PMI).
- Familiaridad con el análisis de datos y la manipulación de datos en Python, utilizando bibliotecas como pandas y numpy.
- Conocimiento de visualización de datos utilizando bibliotecas como matplotlib y seaborn.
- Experiencia en la implementación de aplicaciones web utilizando frameworks como Flask o Django.
- Familiaridad con el uso de herramientas de línea de comandos y la instalación de paquetes de Python utilizando pip.
Instalación de Bibliotecas Necesarias
Empezamos creando un entorno virtual con venv y activándolo:
python -m venv env
source env/bin/activateinstalar las bibliotecas necesarias:
pip install matplotlib pandas numpy nltk gensimDesarrollo del Laboratorio
Conceptos Básicos
Tokenización
La tokenización es el proceso de dividir un texto en unidades más pequeñas, como palabras o frases, llamadas tokens. Es un paso fundamental en el procesamiento de texto para la extracción de información y análisis lingüístico.
Bigrams
Un bigram es una secuencia de dos palabras consecutivas en un texto. Los bigrams son útiles para capturar relaciones entre palabras que no se pueden detectar con palabras individuales.
Colocaciones
Las colocaciones son combinaciones de palabras que ocurren juntas con mayor frecuencia de lo que se esperaría por azar. Detectar colocaciones es esencial para entender el contexto en el que se utilizan ciertas palabras.
Desarrollo del Laboratorio
Paso 0: Creamos el Notebook
Creamos un nuevo notebook de Jupyter y lo guardamos como analisis_texto.ipynb . A continuación, importamos las bibliotecas necesarias y descargamos los recursos de NLTK:
Paso 1: Importar Bibliotecas
Primero, importamos las bibliotecas necesarias para el análisis:
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import re
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.collocations import BigramAssocMeasures, BigramCollocationFinder
from gensim.models.phrases import Phrases, Phraser
# Descargar recursos necesarios de NLTK
nltk.download('punkt')
nltk.download('reuters')
from nltk.corpus import reutersExplicación: Estas bibliotecas proporcionan las herramientas necesarias para la tokenización, la detección de bigrams y el análisis de colocaciones. También descargamos el corpus de Reuters para usarlo en nuestros ejemplos.
Paso 2: Cargar y Preparar el Corpus
Vamos a cargar el corpus de Reuters y preparar los documentos para el análisis:
documents = [reuters.raw(fileid).lower() for fileid in reuters.fileids()]
# Ver el primer documento
print(documents[0])Explicación: El corpus de Reuters se compone de varios documentos de texto. En esta celda, cargamos todos los documentos y los convertimos a minúsculas para normalizar el texto.
Paso 3: Tokenización
Tokenizamos el corpus en palabras para procesar los bigramas:
tokens = [word for doc in documents for word in word_tokenize(doc)]
print(tokens[:15])Explicación: Aquí convertimos cada documento en una lista de palabras (tokens). Esto es crucial para los análisis posteriores, ya que necesitamos trabajar con unidades básicas de texto.
Paso 4: Detección de Bigramas con NLTK
Utilizamos NLTK para encontrar bigramas y aplicamos un filtro para remover aquellos con una frecuencia menor a 10:
bigram_measures = BigramAssocMeasures()
finder = BigramCollocationFinder.from_words(tokens)
finder.apply_freq_filter(10)
bigramas = finder.nbest(bigram_measures.pmi, n=50)
print(bigramas)Explicación: Usamos BigramCollocationFinder para encontrar bigramas en el texto tokenizado. Aplicamos un filtro para eliminar bigramas que aparezcan con poca frecuencia (menos de 10 veces) y seleccionamos los 50 más significativos según la medida PMI (Pointwise Mutual Information).
Paso 5: Detección de Colocaciones con Gensim
Ahora, utilizamos Gensim para detectar colocaciones en el texto:
sentences = [word_tokenize(sent) for sent in sent_tokenize("\n".join(documents).lower())]
sentences = [sent for sent in sentences if len(sent) > 1]
collocations = Phrases(sentences=sentences, min_count=10, threshold=0.5, scoring='npmi')
to_collocations = Phraser(collocations)
sent = 'new york is in united states of america. south africa and south america are in different continents'
print(to_collocations[word_tokenize(sent)])Explicación: Gensim se utiliza aquí para detectar colocaciones a partir de oraciones tokenizadas. El modelo de Phrases permite identificar secuencias de palabras que tienden a aparecer juntas. En este ejemplo, demostramos cómo funciona usando una oración de prueba.
Paso 6: Análisis de Colocaciones
Finalmente, analizamos y mostramos las colocaciones más significativas:
# Crear el objeto BigramCollocationFinder
collocations = BigramCollocationFinder.from_words(tokens)
# Usar BigramAssocMeasures para obtener las puntuaciones de los bigramas
scored = collocations.score_ngrams(BigramAssocMeasures().pmi)
# Crear un DataFrame con los bigramas y sus puntuaciones
df_collocations = pd.DataFrame(scored, columns=["bigram", "score"])
# Eliminar duplicados y ordenar por puntuación
df_collocations = df_collocations.drop_duplicates().sort_values(by="score", ascending=False)
# Imprimir los primeros 50 bigramas
print(df_collocations.head(50))Explicación: Este paso combina el análisis de bigramas con la creación de un DataFrame para visualizar las colocaciones más significativas. Usamos el puntaje PMI para ordenar los bigramas según su relevancia.
Guardar el modelo de bigramas
to_collocations.save('bigram_model')Explicación: Guardamos el modelo de bigramas para su uso posterior en la detección de colocaciones.
Implementación de una aplicación web
Para poner en práctica lo aprendido, puedes implementar una aplicación web que permita a los usuarios ingresar texto y detectar automáticamente las colocaciones más significativas. Esto puede ser útil en tareas de análisis de texto y minería de datos.
Paso 0: Creación de la aplicación web:
touch app.py
pip install streamlitImplementación de la aplicación web:
Paso 1: Crear una Interfaz de Usuario
Utiliza una biblioteca como Streamlit para crear una interfaz de usuario simple donde los usuarios puedan ingresar texto y ver las colocaciones detectadas.
import streamlit as st
st.title("Detección de Colocaciones en Texto")
# Ingresar texto
text = st.text_area("Ingrese un texto:")Paso 2: Procesar el Texto Ingresado
Utiliza el modelo de bigramas guardado para detectar colocaciones en el texto ingresado por el usuario.
from gensim.models.phrases import Phraser
# Cargar el modelo de bigramas
to_collocations = Phraser.load('bigram_model')
# Tokenizar el texto ingresado
tokens = word_tokenize(text.lower())
# Aplicar el modelo de bigramas
colocaciones = to_collocations[tokens]
# Mostrar las colocaciones detectadas
st.write("Colocaciones Detectadas:")
st.write(colocaciones)Paso 3: Mostrar las Colocaciones Detectadas
Muestra las colocaciones más significativas en la interfaz de usuario para que los usuarios puedan verlas y analizarlas.
# Mostrar las colocaciones en una tabla
st.write("Colocaciones Detectadas:")
st.write(pd.Series(colocaciones).value_counts())Paso 4: Ejecutar la Aplicación
Ejecuta la aplicación web y prueba la detección de colocaciones con diferentes textos de entrada.
streamlit run app.pyProbar la aplicación con estos ejemplos
Ejemplo 1: Artículo de Noticias
The stock market is showing signs of recovery as major indices reported gains for the third consecutive day. Investors remain cautious, however, as inflation rates continue to rise globally.Ejemplo 2: Descripción de un Lugar
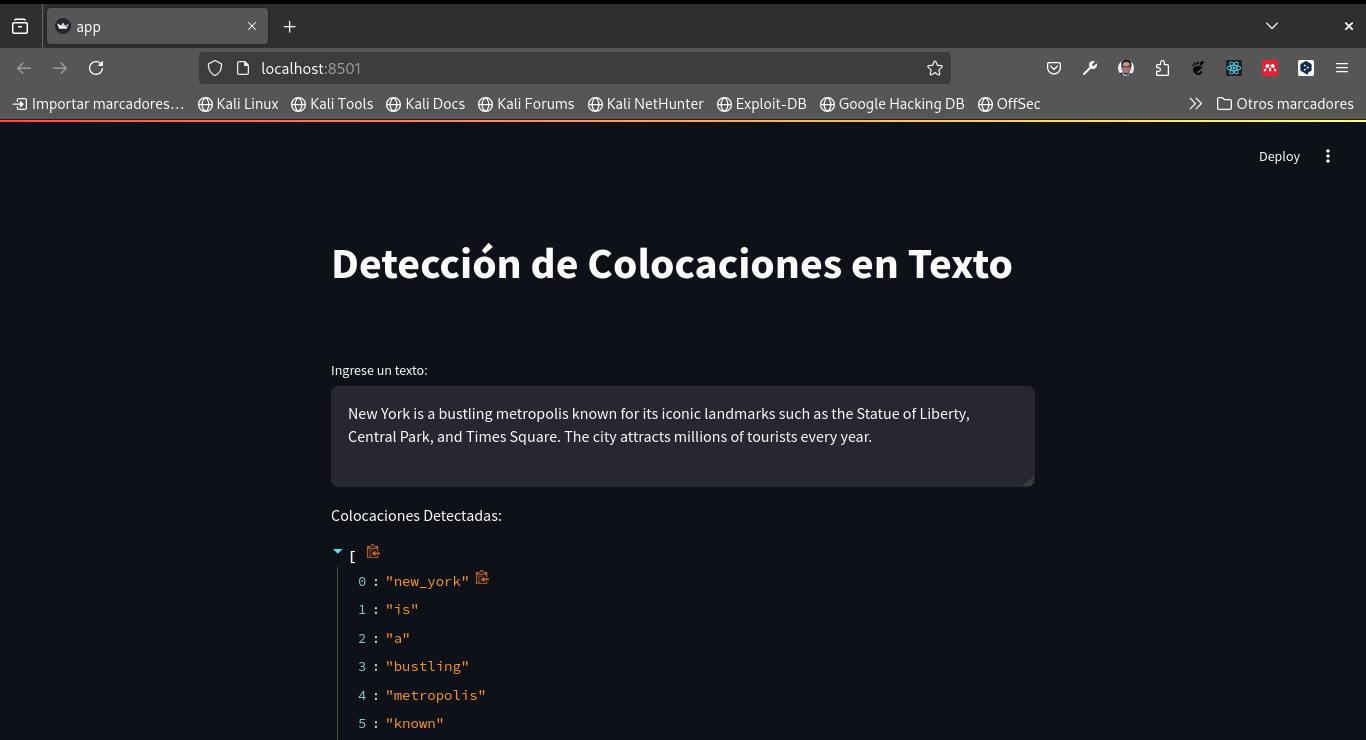
New York is a bustling metropolis known for its iconic landmarks such as the Statue of Liberty, Central Park, and Times Square. The city attracts millions of tourists every year.Ejemplo 3: Texto Literario
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity.Ejemplo 4: Texto Técnico
Machine learning is a subset of artificial intelligence that focuses on the development of algorithms that can learn and make predictions based on data. Neural networks, support vector machines, and decision trees are common models used in this field.Ejemplo 5: Texto de una Conversación
Hey, how are you doing today? I was thinking we could go to the park later if the weather is nice. What do you think?Cada uno de estos ejemplos te permitirá observar cómo el modelo detecta bigramas y colocaciones en distintos tipos de texto, desde descripciones técnicas hasta conversaciones informales.
Reto
Como reto adicional, puedes intentar mejorar la detección de colocaciones utilizando otros modelos de bigramas o trigramas, como los proporcionados por NLTK o spaCy. También puedes explorar la detección de colocaciones en otros idiomas o en textos especializados, como documentos médicos o legales.
Recursos
Conclusiones
En este laboratorio, hemos aprendido a utilizar herramientas de procesamiento de lenguaje natural (NLP) para analizar texto, detectar bigramas y colocaciones significativas. Hemos utilizado bibliotecas populares como NLTK y Gensim para realizar estas tareas y hemos implementado una aplicación web para demostrar la detección de colocaciones en texto ingresado por el usuario. Este conocimiento es fundamental para tareas de análisis de texto y minería de datos en diversos campos de aplicación.